Dijkstra's Algorithm
Dijkstra’s algorithm finds shortest paths from the starting node to all nodes of the graph, like the Bellman–Ford algorithm. The benefit of Dijkstra’s algorithm is that it is more efficient and can be used for processing large graphs. However, the algorithm requires that there are no negative weight edges in the graph.
Algorithm
Like the Bellman–Ford algorithm, Dijkstra’s algorithm maintains distances to the nodes and reduces them during the search. At each step, Dijkstra’s algorithm selects a node that has not been processed yet and whose distance is as small as possible. Then, the algorithm goes through all edges that start at the node and reduces the distances using them. Dijkstra’s algorithm is efficient, because it only processes each edge in the graph once, using the fact that there are no negative edges.
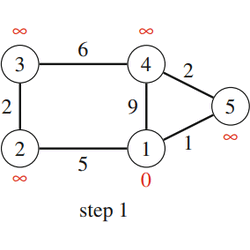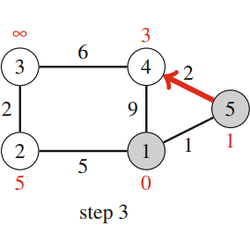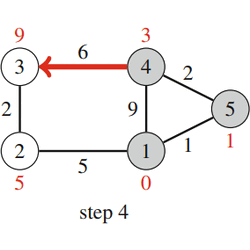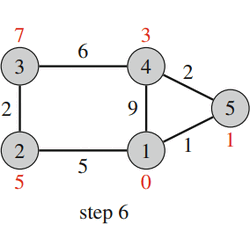 |
|---|
| Fig. 20: Dijkstra's Algorithm |
Fig. 20 shows how Dijkstra’s algorithm processes a graph. Like in the Bellman–Ford algorithm, the initial distance to all nodes, except for the starting node, is infinite. The algorithm processes the nodes in the order 1, 5, 4, 2, 3, and at each node reduces distances using edges that start at the node. Note that the distance to a node never changes after processing the node.
Implementation
An efficient implementation of Dijkstra’s algorithm requires that we can efficiently find the minimum-distance node that has not been processed. An appropriate data structure for this is a priority queue that contains the remaining nodes ordered by their distances. Using a priority queue, the next node to be processed can be retrieved in logarithmic time.
A typical textbook implementation of Dijkstra’s algorithm uses a priority queue that has an operation for modifying a value in the queue. This allows us to have a single instance of each node in the queue and update its distance when needed. However, standard library priority queues do not provide such an operation, and a somewhat different implementation is usually used in competitive programming.
The idea is to add a new instance of a node to the priority queue always when its distance changes.
Our implementation of Dijkstra’s algorithm calculates the minimum distances from a node x to all other nodes of the graph. The graph is stored as adjacency lists so that adj[a] contains a pair (b, w) always when there is an edge from node a to node b with weight w. The priority queue priority_queue<pair<int,int>> q; contains pairs of the form (−d, x), meaning that the current distance to node x is d.
The array distance contains the distance to each node, and the array processed indicates whether a node has been processed.
NOTE
- The priority queue contains negative distances to nodes. The reason for this is that the default version of the C++ priority queue finds maximum elements, while we want to find minimum elements.
- While there may be several instances of a node in the priority queue, only the instance with the minimum distance will be processed.
The implementation is as follows:
for (int i = 1; i <= n; i++) {
distance[i] = INF;
}
distance[x] = 0;
q.push({0,x});
while (!q.empty()) {
int a = q.top().second; q.pop();
if (processed[a]) continue;
processed[a] = true;
for (auto u : adj[a]) {
int b = u.first, w = u.second;
if (distance[a]+w < distance[b]) {
distance[b] = distance[a]+w;
q.push({-distance[b],b});
}
}
}
Negative Edges
 |
|---|
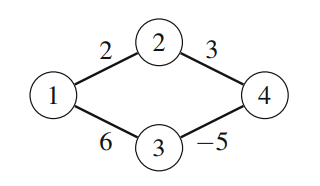
| Fig. 21: A graph where Dijkstra's algorithm fails |
The efficiency of Dijkstra’s algorithm is based on the fact that the graph does not have negative edges. However, if the graph has a negative edge, the algorithm may give incorrect results. As an example, consider the graph in Fig. 21.
The shortest path from node 1 to node 4 is and its length is 1. However, Dijkstra’s algorithm incorrectly finds the path by greedily following minimum weight edges.