Breadth-First Search (BFS)
Breadth-first search (BFS) visits the nodes of a graph in increasing order of their distance from the starting node. Thus, we can calculate the distance from the starting node to all other nodes using breadth-first search. However, breadth-first search is more difficult to implement than depth-first search.
Algorithm
Breadth-first search goes through the nodes one level after another. First the search explores the nodes whose distance from the starting node is 1, then the nodes whose distance is 2, and so on. This process continues until all nodes have been visited.
 |
|---|
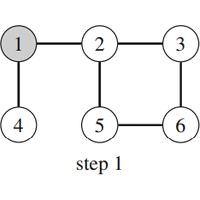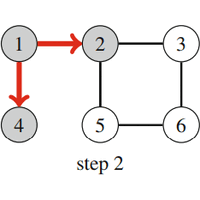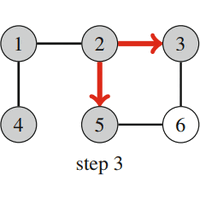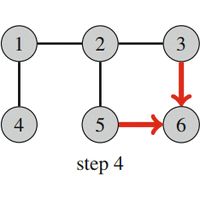
| Fig. 14: Breadth-First Search |
Figure 14 shows how breadth-first search processes a graph. Suppose that the search begins at node 1. First the search visits nodes 2 and 4 with distance 1, then nodes 3 and 5 with distance 2, and finally node 6 with distance 3.
Implementation
Breadth-first search is more difficult to implement than depth-first search, because the algorithm visits nodes in different parts of the graph. A typical implementation is based on a queue that contains nodes. At each step, the next node in the queue will be processed.
The queue q contains nodes to be processed in increasing order of their distance. New nodes are always added to the end of the queue, and the node at the beginning of the queue is the next node to be processed. The array visited indicates which nodes the search has already visited, and the array distance will contain the distances from the starting node to all nodes of the graph.
The search can be implemented as follows, starting at node x:
queue<int> q;
bool visited[N];
visited[x] = true;
q.push(x);
while (!q.empty()) {
int s = q.front(); q.pop();
// process node s
for (auto u : adj[s]) {
if (visited[u]) continue;
visited[u] = true;
q.push(u);
}
}
Like in depth-first search, the time complexity of breadth-first search is , where n is the number of nodes and m is the number of edges.